Data Engine — data management tool for ML Engineers from design to shipment
How we imagined, pitched, defined and eventually pivoted the company with a data management tool for ML Engineers
- Time period: September 2023 - now
- Client: DagsHub
- My role: Lead Product Designer
- Feature in production
Context
I transitioned from a six-person product team in a large company to being a solo designer at a startup. This required quickly adapting to new methodologies, learning a new domain, and getting familiar with dev tools in general. It was a big challenge, but also an exciting opportunity to grow and make a real impact.
Problem space: How do ML Engineers work with data?
The Data Engine feature project was initiated to pivot the company’s efforts toward focusing product on unstructured data management. Data is a crucial and challenging component for Data Scientists and ML Engineers, especially when managing models in production and maintaining data pipelines for machine learning projects. To illustrate this cycle, here’s a PM diagram, which shows a value proposition defined for this feature.
 Machine Learning development cycle - value proposition
Machine Learning development cycle - value proposition
Goals and KPIs
Before we started working, there was no easy way to visualize and filter data on the platform. The infrastructure resembled git directories, without adaptation for different types of data, like images, audio, video, tabular etc. Additionally, there was a clear need for advanced querying component, which would fit common practices for ML Engineers and other user personas, such as Annotators or ML Team Leads, who are the potential users of this feature.
The goals we set for this feature included (from the UX point of view):
- Seamless integration into existing git-like infrastructure
- Early validation of the design
- Find ways to simplify the complexity of the tech requirements
- Address different types of personas (technical and non-technical)
On the product side of things, we set the following KPIs:
- Close 3 deals for paying customers which will include at least 15 seats. At that time we had 5 current customers
- Increase the number of engaged users by 20% - from 220 to 264 users
Navigating the unknown
Initially, the feature definition was very broad and vague. Given the scale and the extensive technical effort needed, my questions at the initial stage of the project remained unanswered, both from the dev leads and product stakeholders. At that point I could not gather a lot of information on the details of the implementation.
How do ML Engineers work with data? What needs do they have?
How do they filter their data? What kind of filters do they need?
What are their requirements (e.g. input-based, range-based, time/date based, etc.)?
How does the metadata look like? Are there specific categories?
Is there one-to-one relationship between the metadata field and the value? etc.
POC: Sales demos
We needed to move fast, and to test our product hypothesis with potential customers, despite undefined requirements. The first design version was a sales mock prototype. During the sales pitch, we asked for feedback from potential clients. For my mock I decided to lean on my experience working with data in the library’s catalog and search experience (see NLI search engine redesign), then refine and iterate on the way.
The demo confirmed our hypothesis. The solution we showed made sense, providing transparency and visibility of the data in model development projects.
Research and design
Competitor benchmark
I began by researching competitor products, noting design choices and elements. I reviewed 10 competitor products to understand how they solved common UX problems like search and filtering, metadata display, and integrating code, data, and models. This provided a broad view of the market landscape
 Data management tools on the market
Data management tools on the market
First design mock
I designed a general solution to give the team a sense of the feature’s potential look and functionality. I also hoped to get more specific feedback and questions once the team will see the proposed solution visually.
As the first designer in the company, in parallel I was establishing the first Design System for the product, so I was designing and documenting every component for it.
Domain expert interviews
With the initial design ready, and in parallel to sales demos, the PM and I conducted interviews with potential customers to understand their needs and gather feedback.

Here are some things they mentioned:
“I think that a big part of the value is to provide the API and not just the UI … when you talk about researchers that watch large datasets”.
“Most researches work via programming, it will be more natural for them to use”.
“It will allow researchers to integrate this with other tools they are using easily… for example, add function at the end of each training that generates the results visually…instead of trying to create this display again in the UI, I know what will be interesting for me to see at the end of each training so I’ll automatically have it generated”.
This feedback led us to prioritize building the backend API first while seeking ways to deliver value with these capabilities.
Design partnerships
To refine the design and specifications, we adopted a “design partnership” strategy. During sales talks, we presented the design mockup, explained the value proposition, and offered discounts for feedback during development. This approach proved beneficial, helping us better define and improve the product based on real user input.
As a result, my understanding of the technical requirements for the feature evolved. In parallel I refined my mock as our dev team was building the first backend API capabilities.
Some of my questions still remained unanswered, and some of the clients’ requests were very specific for their use case, but overall, having these inputs proved to be very valuable, as we did not act in vacuum and expanded our list of paying customers.
Iterative Design and Feedback
After a series of customers’ and potential customers’ interviews, together with the PM, we worked on defining the user flow for the feature. Things were starting to get much more clear.
User flows

We worked closely with the PM, dev lead, and CTO to define the scope for the first MVP. The final design focused on essential elements for the MVP.
Ongoing Development and Feedback
In roughly 8 months we successfully rolled out the feature. We’re receiving feedback from our design partners and gradually add new capabilities, fix bugs and enhance user experience. I’m listening and observing closely the usage of the feature.
Here are some of the inputs received:
“Wouldn’t incorporating a text editor be a valuable addition, providing more than just query construction? What are your thoughts on implementing queries similar to SQL?”
“It’s great that the query is fully translatable between UI and text!”
”I think it is very useful to see the number of items in each dataset from the main “Sources” page. Maybe also “created by”? and “tags” attached to each dataset.”
Conclusion
Here’s a current state of the Data Engine feature in production (link):
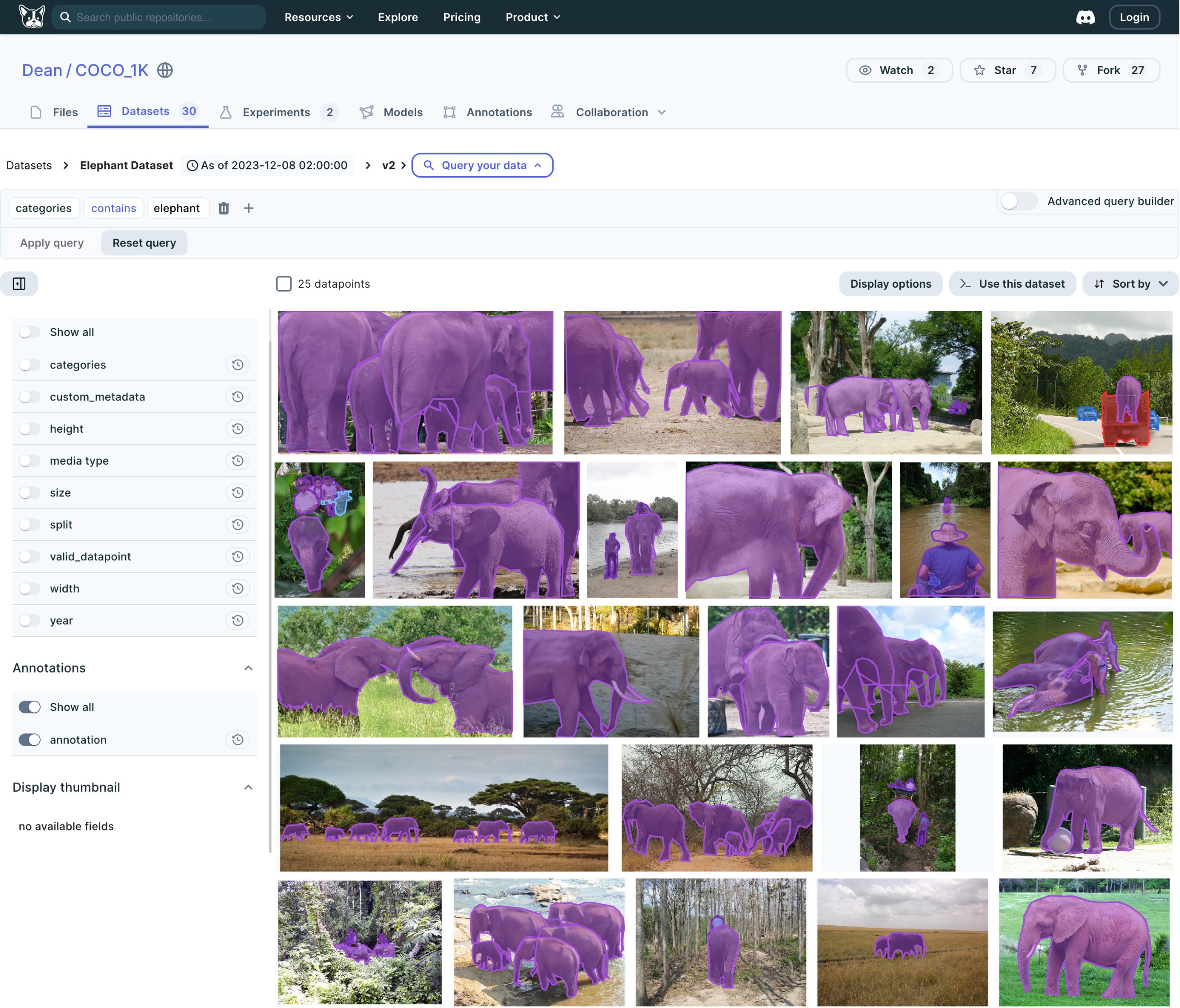
The feature is still rolling out, and I’m listening and watching closely to user feedback. Overall, it received very good responses both from the clients and from the stakeholders.
We were able to double the amount of paying customers by offering this feature roughly in three months to half a year.